(blog)obsidian link를 그대로 github.io에 적용하기
[2024-08-15] 2024-08-08-Github 블로그 꾸며보기2 파일이 지나치게 길어져 별도의 파일로 분리합니다. 또, Liquid 문법 상 이중 중괄호가 감지되면
liquid문법으로 치환하려고 해서{하나만 inline code block으로 표기합니다.
(실패)jekyll-relative-links Plugin 적용
markdown [다른 파일]({{ site.baseurl }}/sitebaseurl) 링크를 걸고 싶으면 여기 플러그인을 설치해야 한다.
1
gem install jekyll-relative-links
성공적으로 설치가 되었다면 [이전 글]({{ site.baseurl }}/sitebaseurlposts)을 참조해야 하는데.. 잘 안된다. 이 플러그인은 현재 주소 뒤(ex. baseurl/posts/현재문서)에 /을 붙이고 그대로 뒤에 주소를 붙이는 방식을 택하고 있는데, 이렇게 하면 엉뚱한 주소를 참조하게 된다.
(실패)Ruby 스크립트로 커스텀 플러그인 만들어보기
Ruby는 다뤄보지 않아서 위 규칙에 맞는 코드를 작성해달라고 chatGPT에게 도움을 요청했다.
- path :
/_plugins/obsidian_link_converter.rb _config.yml파일에plugins항목에 추가할 것.
1
2
plugins:
- obsidian_link_converter
그럼에도 불구하고 여전히 동작하지 않는다. 그리고 사실 Github Action은 보안문제로 커스텀 plugin이 있으면 빌드취소하고 에러를 뱉는다. 어쩔 수 없이 스크립트를 만들어서 Action에서 별도로 변환시켜주는 workflow를 추가해야만 한다.
Python 스크립트 만들기
아래 relative-link 구현하는 용도로 만든 dummy header 입니다. 특수문자 1!2@3#4$5%6^7&8*9.0,a;b c<>d+e{}f-g_ 어떻게 보일까요?
일단 obsidian의 규칙을 좀 더 파악해보자. 참고로 아래 링크는 옵시디언에서는 작동이 안 되는데 블로그에서는 정상적으로 작동된다.
1
2
`[아래 relative-link 구현하는 용도로 만든 dummy header 입니다. 특수문자 1!2@3#4$5%6^7&8*9.0,a;b c<>d e{} 어떻게 보일까요?]
(#아래-relative-link-구현하는-용도로-만든-dummy-header-입니다-특수문자-1234567890ab-cdef-g_-어떻게-보일까요)`
- 같은 문서 내 heading 참조 :
[1. File & links](#1-File-amp-links) - 다른 문서 참조 :
[2024-08-04-Github.io블로그 꾸며보기]({{ site.baseurl }}/posts) - 다른 문서 내 heading 참조 :
[댓글 기능 구현하기]({{ site.baseurl }}/posts#--)
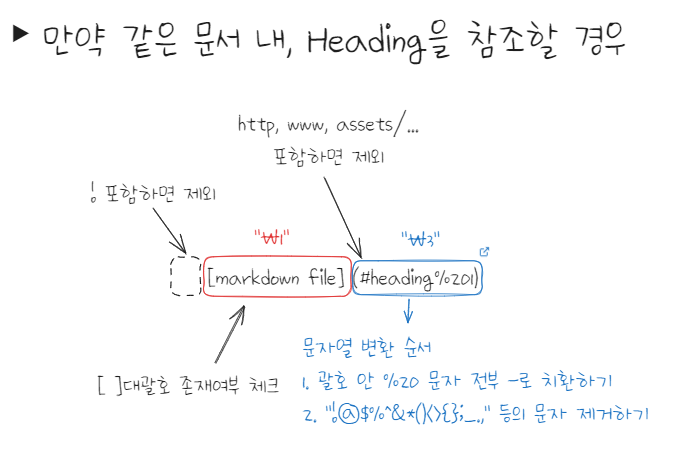
분석 및 설계
() 안의 문자열을 어떻게 수정할지 순서를 고려해보면서 생각해보자.
- 2024-08-16에 수정한 내용 반영
- ”`“나
!으로 시작하는 건 inline code block이나 image 임베드 문법이니 감지되면 제외한다.()안에서 처음 시작하는 문자가http나www,assets/img/...등을 포함하면 안 된다.
- 외부 인터넷 링크 혹은 이미지라고 판단 되면 포함하면 해당 문자열은 변환하지 않는다.
- 모든 영문자는 소문자로 치환한다.
- [2024-08-16] 소문자 치환은 Heading 부분만 치환한다. 글 제목은 치환하면 안 된다.
- 모든
%20(띄어쓰기)은-로 치환한다.- 다른 문서를 참조할 때
- 날짜형식
yyyy-mm-dd-은{baseurl}/posts/로 바꾼다..md문자열을/로 변환한다.- 아래 heading과 다르게 제목에
.,&!등의 특수문자가 포함되어도 되니 이러한 특수문자는 제거하지 않도록 주의한다.- 다른 heading을 참조할 때(다른 문서도 포함)
#문자가 포함되어 있을 경우/#을 현재주소 뒤에 붙인다.
- 이미 다른 heading을 참조 중일 때는
/#이전까지만 가져와서 주소를 이어붙인다.- heading
!@#$%^&*()[]{},.{}()[]<>?+_/등의 특수문자들은 그냥 제거한다.
-는-로 표기된다.- obsidian의 경우 일부 문자열을 사용하지 않는다.
- 이 때의 첫 번째로 오는
#는 Heading이 아니라 특수문자로 취급한다.- heading 만 있을 경우
#heading만 남긴다(리다이렉트 X)
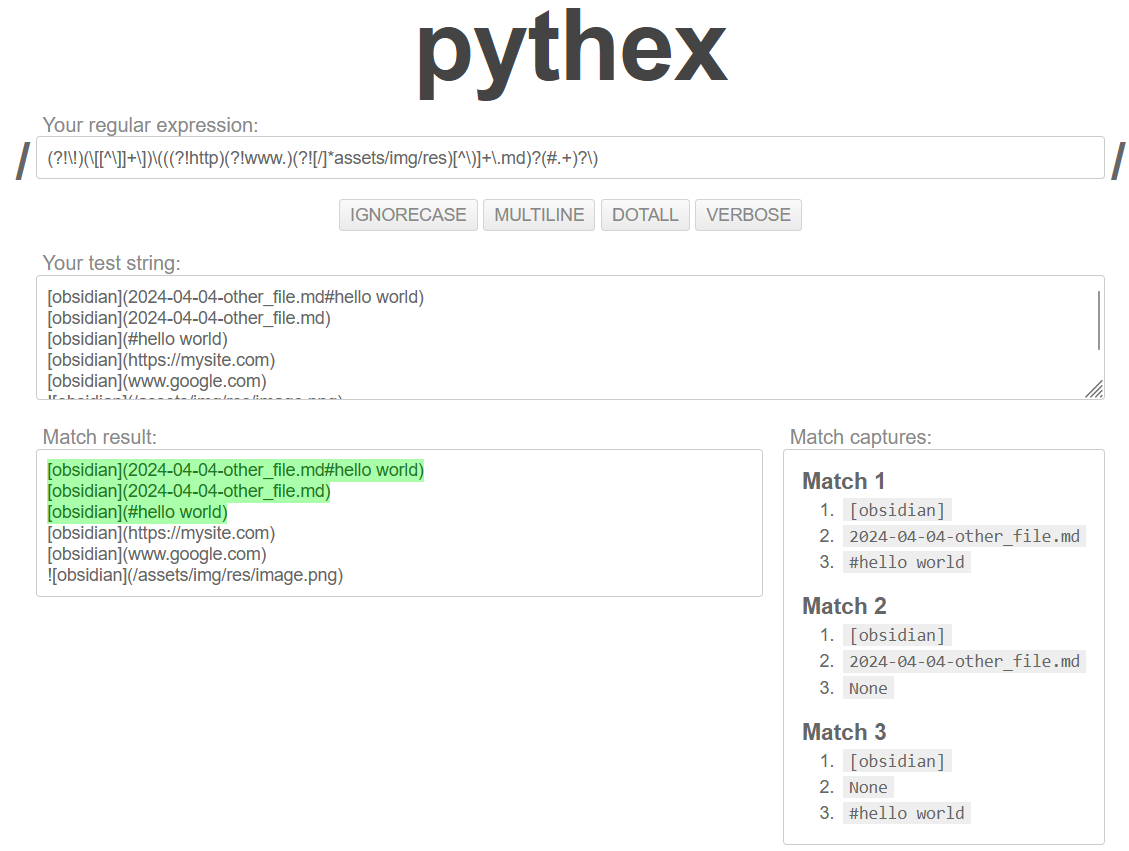
Pythex: a Python regular expression editor
Pythex is a real-time regular expression editor for Python, a quick way to test your regular expressions.
아래와 같이 expression 짜주면 http, www을 포함한 주소링크를 무시해준다.  그리고 위 정규표현식을
그리고 위 정규표현식을 [],() 해당하는 부분을 따로 소괄호로 묶어주면 2개의 결과물을 얻을 수 있다.
(\[[^\]]+\])(\((?!http)(?!www.)[^\)]+\))
우리는 저 두 번째 부분을 받아와서 변환해야 한다.
그러면 어떤 문자열로 변환해야 정확한 링크로 변환해줄까? 성공적으로 변환한 것만 체크해뒀다.
- 일반 링크
[구현단계 ABC](#-ABC) %20-로 치환 + 소문자 치환[구현단계 ABC](#-abc)- 구현단계 ABC
- Python 스크립트 만들기
- 위 두 링크를 번갈아가며 클릭해도 정상적으로 동작한다.
- liquid 문법1
[구현단계 ABC]({{ site.baseurl }}/posts#-ABC)[구현단계 ABC]({{ site.baseurl }}/posts#-ABC)post.url문구가 접근이 안 된다.
- liquid 문법2 + 소문자 치환 +
%20치환[구현단계 ABC](#-abc)][구현단계 ABC]({{ site.baseurl }}/postsrelative-links#-abc)- 오류 때문에 inline code block 처리
site.baseurl은 접근해도 괜찮다.
- 다른 문서 참고하기
[1. linkpreview.html]({{ site.baseurl }}/postslinkpreview-#1-linkpreviewhtml)
위 노가다를 통해 다음과 같이 정리할 수 있다.

위 요구사항을 만족하는 정규표현식은 다음과 같다.
1
(?!\!)(\[[^\]]+\])\(((?!http)(?!www.)(?![/]*assets/img/res)[^\)]+\.md)?(#.+)?\)
구현단계 ABC
(ABC 붙인 이유는 %20 포함여부, 대문자 포함시 어떻게 되는지 확인하는 용도다.)
Step1. python 스크립트 작성하기
_plugins 아래에 link_converter.py를 만든다.
1
2
3
4
5
6
7
8
9
10
11
12
import os
import re
dir = os.getcwd()
input_dir = dir + '/_posts/'
for filename in os.listdir(input_dir) :
if filename.endswith(".md") :
filepath = os.path.join(input_dir, filename)
with open(filepath, "r", encoding="UTF-8") as file :
content = file.read()
content = re.sub(r"(\[[^\]]+\])\(((?!http)(?!www.)(?![/]*assets/img/res)[^\)]+\.md)?(#.+)?\)", regex_rule, content)
아까 위에서 ![]()에서 !포함되면 제외하는 이유다. print로 결과창을 보면 /assets도 포함되어 있는데 보통 이미지 파일들이 으로 구현되어 있다. 그래서 assets/img을 제외하는 문구와 가장 앞에 !를 제외하도록 다시 수정한다.
Step2. python 정규표현식 group 메소드 활용하기
우리가 변환할 정규표현식은 까다롭다. 아래 첨부된 블로그 글을 보면 str.replace >>>>>> re.sub >> str.translate 순서로 빠른데 우리는 긴 글을 여러 번 반복해서 아무 문자를 붙잡고 re.sub("\W", "", content)치환하게 된다면 Build하는데 오래걸릴 수 밖에 없다.
그렇기 때문에 content 한 번만 읽고 바꿀 수 있는 문자열은 전부 바꿔야 한다.

[python] 문자열 치환 총 정리 및 성능 비교하기(str.translate, str.replace, re.sub)
목차 Intro 데이터 전처리 과정은 분석 결과/ 모델 성능에 중요한 영향을 미치기에, 데이터 전처리 과정에서 데이터 정제에 속하는 문자열을 치환하는 방법을 제대로 이해하고자 합니다. 파이썬 문자열 내장 함수인 str.translate(), str.replace(), 그리고 re 모듈을 활용한 re.sub을 이용한 문자열 치환 방법을 알아보겠습니다. * 데이터 전처리: 데이터 정제 > 결측값 처리 > 이상값 처리 > 분석 변수 처리순으로 진행됨 * 데이터 정제: 결측값(missing value)을 채우거나 이상값(outlier)을 제거하는 과정으로 데이터의 신뢰도를 높이는 작업 str.translate s = '\nNew Jeans\t' table = s.maketrans({'\n':'', '\t':''..
앞에서 정리한 두 케이스를 조금 더 보충하면서 한 눈에 보이도록 수정하겠다. (아직 아래 사진은 업데이트 안 함.. #미완성) 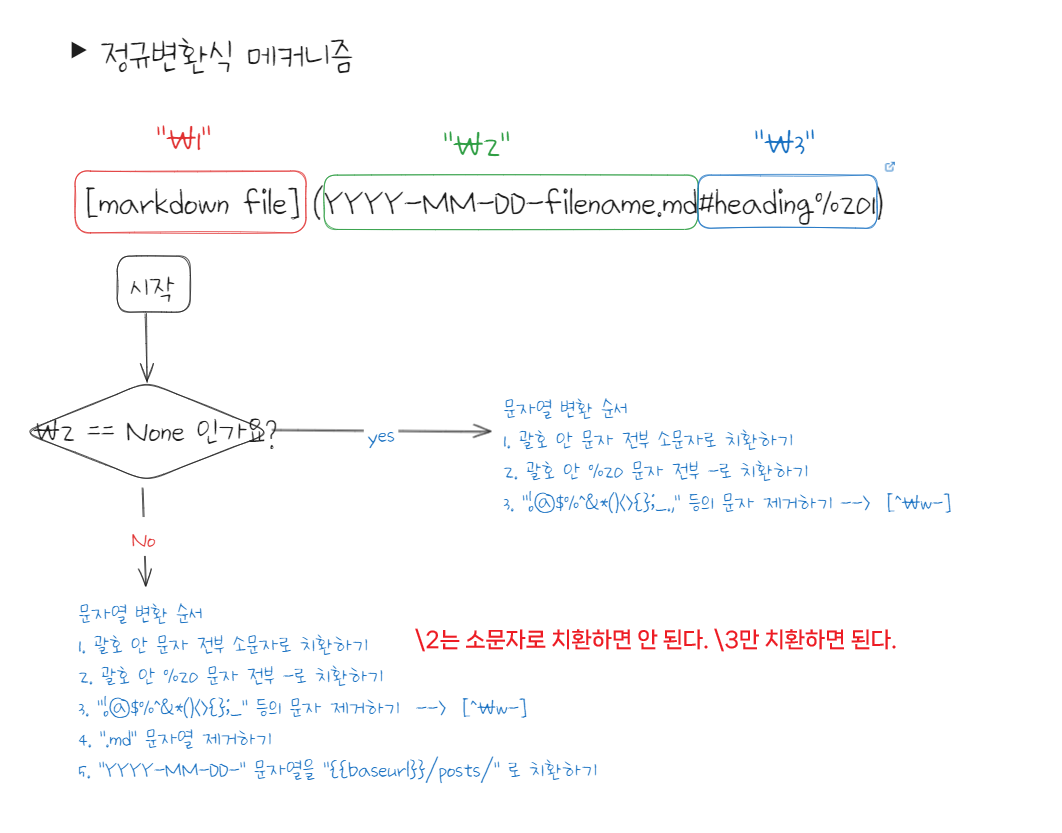
다행히도 re.sub안에 함수를 넣어 위 과정을 한 번에 처리할 방법이 있다. 위 규칙에 맞는 함수를 만들어보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
import os
import re
import sys
dir = os.getcwd()
input_dir = dir + '/_posts/'
def regex_rule(match) :
alias = match.group(1)
other_file = match.group(2)
heading = match.group(3)
other_file = "" if other_file is None else other_file # 빈 문자열도 false로 인식
heading = "" if heading is None else heading
#1. %20 => "-" 그리고 소문자로 치환하기
other_file = other_file.replace("%20", "-")
heading = heading.replace("%20", "-").lower()
#2. 특수문자 모두 제거
other_file = re.sub(r"[^\w-]","",other_file)
heading = "#" + re.sub(r"[^\w-]","",heading) if heading != "" else ""
if other_file :
#3. .md 제거하기 #2에서 "." 이미 제거됨.
other_file = other_file[:-2] if len(other_file)>2 and other_file[-2:] == "md" else other_file
#4. 날짜를 다음 문자로 치환하기
other_file = re.sub(r"\d{4}-\d{2}-\d{2}-", "/posts/", other_file)
return alias + "(" + other_file + heading +")"
for filename in os.listdir(input_dir) :
if filename.endswith(".md") :
filepath = os.path.join(input_dir, filename)
with open(filepath, "r", encoding="UTF-8") as file :
content = file.read()
content = re.sub(r"(?!\!)(\[[^\]]+\])\(((?!http)(?!www.)(?![/]*assets/img/res)[^\)]+\.md)?(#.+)?\)", regex_rule, content)
regex_rule 함수는 \1, \2, \3 모두 따로 구분해서 인식한다. 반환하고 싶은 문자열이 있다면 return에 문자열을 반환하면 된다.
위 코드에서 마지막 코드 3줄만 수정하면 된다.
1
2
3
4
5
6
7
8
with open(filepath, "r", encoding="UTF-8") as file :
content = file.read()
content = re.sub(r"(?!\!)(\[[^\]]+\])\(((?!http)(?!www.)(?![/]*assets/img/res)[^\)]+\.md)?(#.+)?\)", regex_rule, content)
if sys.platform.lower() == "linux" :
with open(filepath, "w", encoding="UTF-8") as file :
file.write(content)
else :
print(f"os platform error : {sys.platform}")
with open(filepath, "w") as file코드를 그대로 바로 실행시키면_posts내 모든 마크다운 파일들의 내용이 삭제되거나 사용할 수 없는 링크로 변환되니 별도의 안전장치 없이 날 것으로 로컬에서 실행하지 않는 것을 권장한다. 실제로 한 번 날려먹어서 내 경우에는 운영체제가Ubuntu일때만(Github Action이 ubuntu 환경이다) 실행하도록 위와 같이 코드를 짰다.
Step3. workflow 설정하기
원래라면 action/setup-python@v5을 설치하는 과정을 가져야 하는데 Repository를 찾을 수 없다는 에러문구가 뜬다.
그렇기 때문에 .github/workflow 내 yml 파일에서 Setup Ruby 전에 다음 문구를 입력하자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
jobs:
build:
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v4
with:
fetch-depth: 0
# submodules: true
# If using the 'assets' git submodule from Chirpy Starter, uncomment above
# (See: https://github.com/cotes2020/chirpy-starter/tree/main/assets)
- name: Setup Pages
id: pages
uses: actions/configure-pages@v4
# 여기 추가
- name: Run Python Script for link converter
run: python _plugins/link_converter.py
- name: Setup Ruby
uses: ruby/setup-ruby@v1
with:
ruby-version: 3.3
bundler-cache: true
그러면 처음보는 step이 새로 생기면서 문서 변환이 정상적으로 이뤄진다. 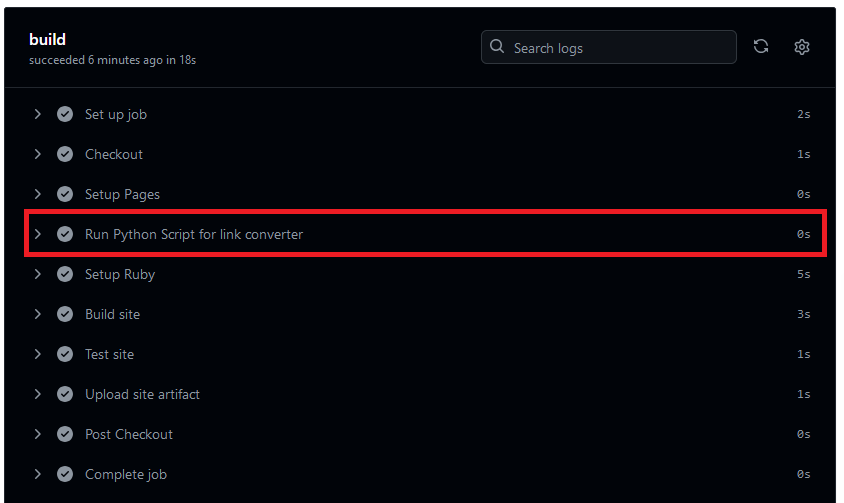
아마 특수한 문자를 쓰는 거 아니면 정상적으로 동작할 것이다. 추후 새 예외사항이 생기면 본 문서에 추가 작성할 예정이다.
매우 긴 글이 되었는데 이제 localhost에서 빌드하는 경우를 제외한다면 obsidian 파일링크와 블로그에서의 링크 둘 다 사용할 수 있게 되었다. 다음 시간에 여기서 좀 더 응용해서 D3-force 와 막대그래프를 활용한 포트폴리오 페이지를 구성할 예정이다. ■
수정사항
2024-08-16
[]()“`” 안 문자도 변환해서 설명하는 문서의 글도 이상하게 변한다. 예외처리해주자. #issue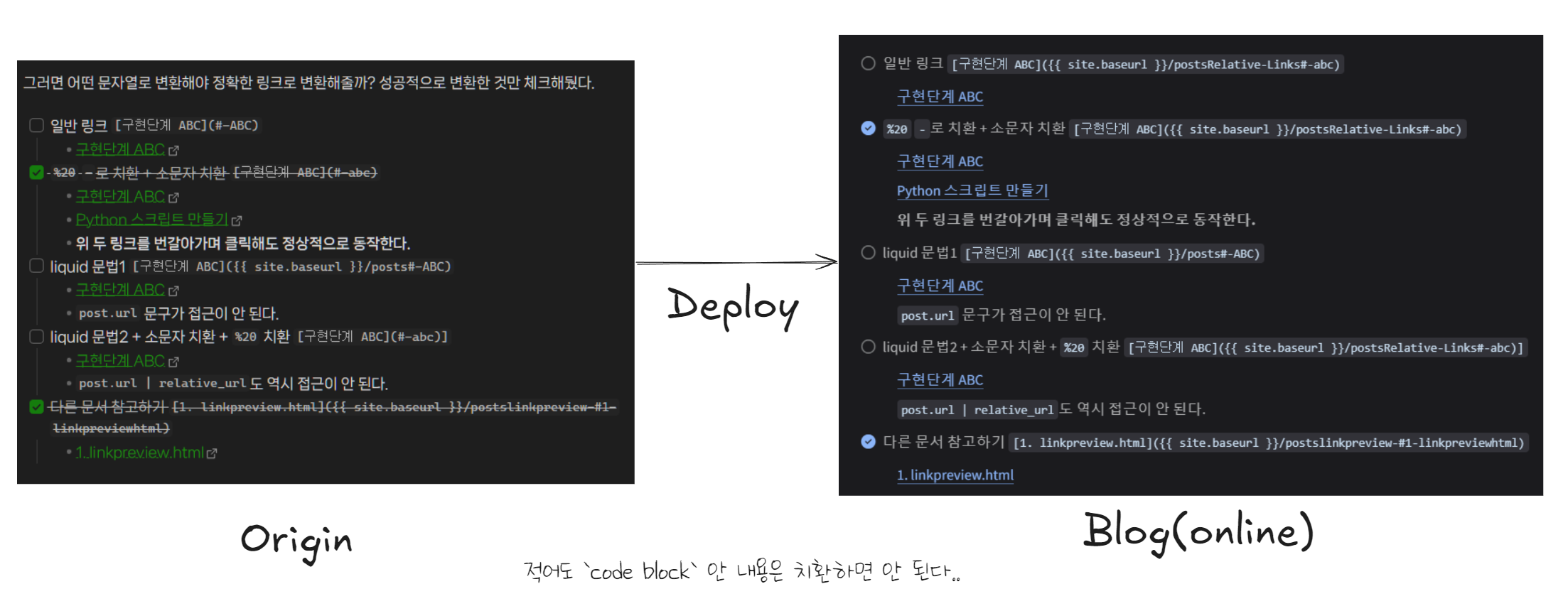
- 정규표현식 수정
- 앞에 “`” 또는
!가 온다면 무시한다. 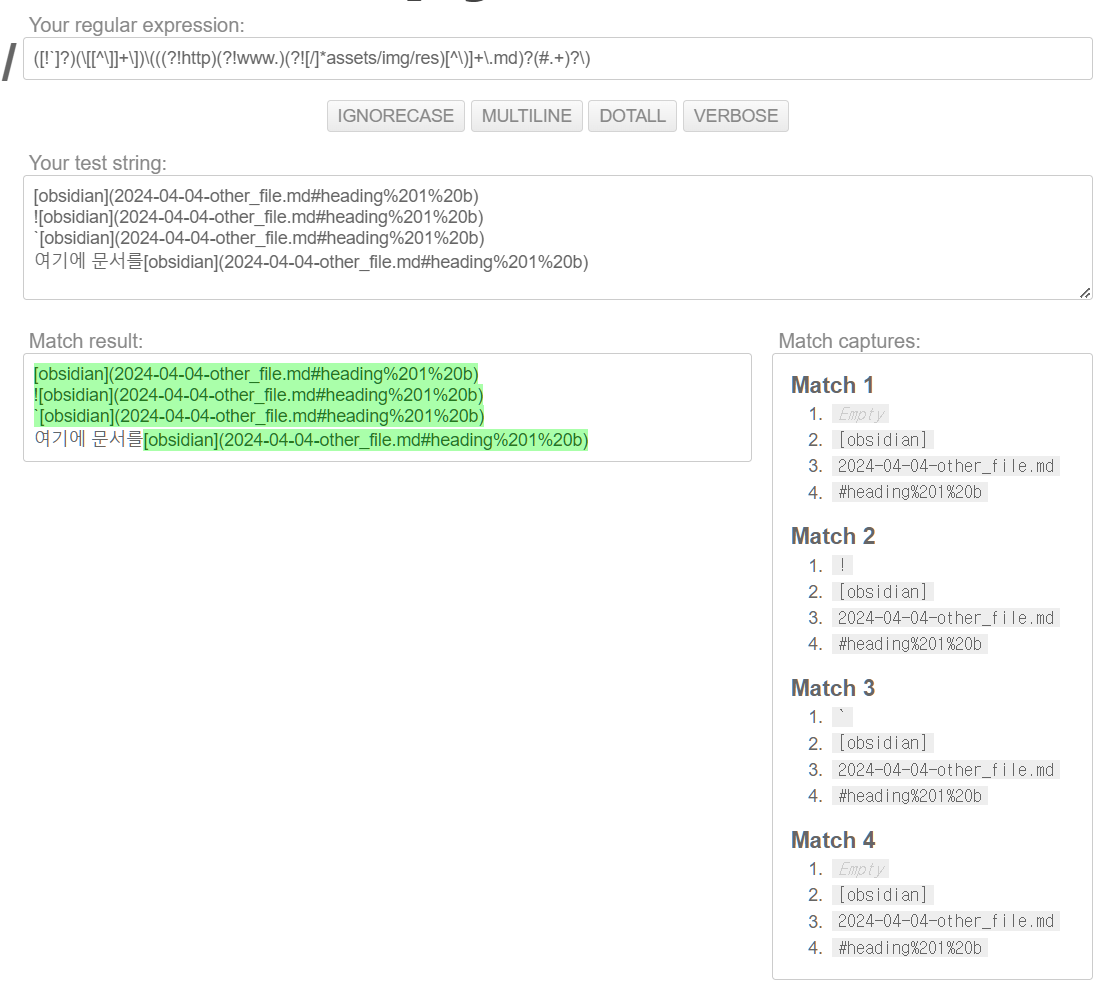
1
2
3
4
5
6
7
8
9
def regex_rule(match, filename = None) :
prefix = match.group(1)
alias = match.group(2)
other_file = match.group(3)
heading = match.group(4)
if prefix is not None :
# !, ` 같은 문자가 오면 원문 그대로 반환할 것.
return prefix + alias + "(" + other_file + heading + ")"
- 인코딩 이슈 #issue
- Github Action에서 정상적으로 변환했음에도 불구하고 한글이 포함된 일부 링크들이 깨진다.
- 그런데 또, 링크주소 복사를 하면 정상적으로 작동된다.
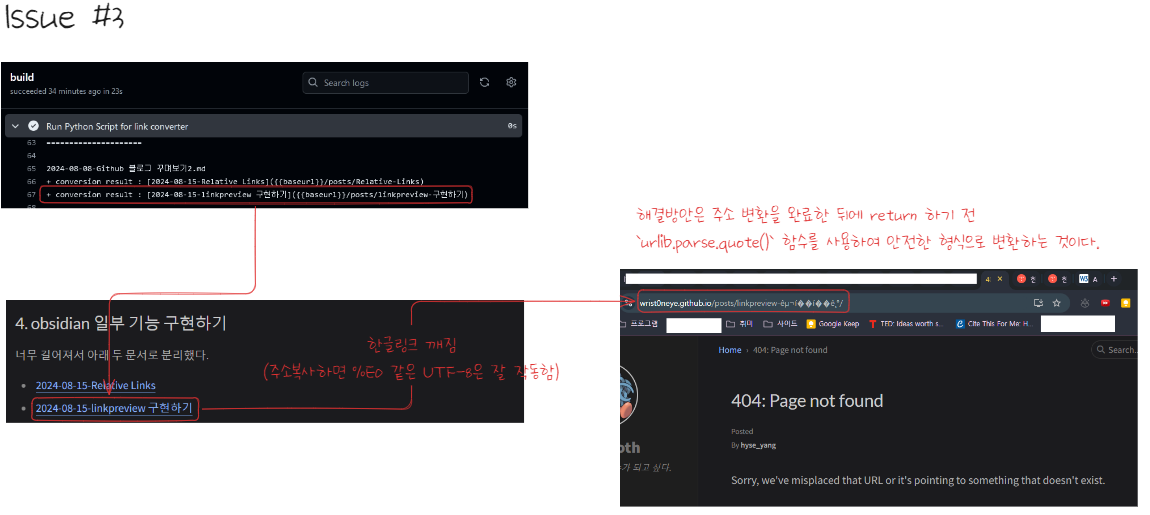
regex_rule함수 마지막에urllib.parse.quote함수로 소괄호 안 주소를 변환해줘야 한다.1 2 3 4 5 6 7 8
#4. 날짜를 다음 문자로 치환하기 # urllib.parse.quote()가 `{`, `}`를 %7B, %7D로 바꿔버려 {baseurl}을 블로그 주소로 변환못하게 만든다. # 따라서 아래와 같이 수정한다. other_file = re.sub(r"\d{4}-\d{2}-\d{2}-", "", other_file) abs_path = "" if other_file == "" else "/posts/" file_path = urllib.prase.quote(other_file)+"/" if other_file != "" else "" heading_path = "" if heading == "" else "#" + urllib.parse.quote(heading[1:]) ret = alias + "(" + abs_path + file_path + heading_path + ")"
다른 문서 참조할 때 꼭
.md문자열을/로 치환하자. 안 그러면 주소값이 깨진다.
주의사항
[이렇게 텍스트]()만 적어놓고 링크 넣는칸을 비워두면a tag is missing a reference에러가 발생하니 비워두지 않도록 주의하자.
여전히 해결이 안 되는 부분들
- obsidian의
[[^]]으로image,paragraph등 컴포넌트 단위로 참조하는 기능을 구현하기 어려워서 여기서는 다루지 않는다.- 옵시디언의 경우 제목에 오는 # 문자는
%20으로 치환되는데 이건 따로 구분할 방법이 없다. 최대한 Heading에#외에도^, [], |등의 특수 문자를 섞어쓰지 않도록 주의한다.- 옵시디언의 문서 임베드
![]()기능은 사용할 수 없다.


Reference
Ruby
Python
Jekyll
- Jekyll url vs baseurl
- Jekyll 마크다운(kramdown) 사용법
- kramdown에서는 각주Footnote
[^fn]기능을 지원한다. 앞으로 문서 글 다듬을 때 사용
- kramdown에서는 각주Footnote