SQLD 1과목 정리하기(1)

회사생활하면서 빅데이터를 다루는 일이 생겼는데 엑셀 파일을 여러 개를 수동으로 관리하게 만들어서 이왕 편하게 만들거면 최적화하기 위해 SQLD를 준비한다. 시키지도 않은 일이긴 한데 안 하면 엑셀관리만 서너시간 이상 걸린다…
시험정보
- 각 과목별 40% 미만 맞췄을 시 과락된다.
- 1과목 : 10문제
- 이론, 암기 성향이 강함
- 2과목 : 40문제
이론 내용
- 데이터 모델링 할 때, ERD 로 단순화/추상화/명확화해야 한다.
데이터 베이스 만드는 과정
- 요구 사항 접수
- 개념적 데이터 모델링 : 단순하게 밑그림을 그려보자.ERD
- 논리적 데이터 모델링 : 좀 더 상세하게 그림을 그려보자. Entity 등 디테일하게 설정
- 물리적 데이터 모델링 : 실제로 데이터베이스를 만들어보자.
- 데이터 베이스에 저장할 수 있게 세팅
1. Entity(개체) 이해하기
Entity: 업무에 필요한 정보를 저장/관리하기 위한 집합적인 명사 개념
Instance(인스턴스) : Entity 집합 내에 존재하는 개별적인 대상
정확하지는 않겠지만 Entity-Instance 관계를 Class-Instance 관계로 뭉끄뜨려서 봐도 될 거 같다. 개념을 담은 개체와 그 개체에 속하는 개별적인 대상이라고 생각하자. (학생 - [학생1, 학생2, 학생3], 학교 - [OO학교, □□학교])
Entity의 특징
- 반드시 업무에서 필요한 대상이고 업무에 사용되어야만 한다.
- 유일한 식별자로 식별이 가능해야 한다.
- 인스턴스가 2개 이상일 것
- 속성이 반드시 2개 이상 존재할 것
- 관계가 하나 이상 존재할 것(단, 코드성, 통계성은 생략 가능)
Entity의 특징
유무형에 따라 분류
유형: 물리적 형태가 있는 개체 직원, 주류, 강사, 고객 등등개념: 물리적 형태가 없는 개체 부서, 과목, 계급 등사건: 업무 수행 중에 발생하는 개체(제일 많이 발생함) 강의, 매출, 주문, 상담 등등
엔터티의 분류
발생시점에 따라 분류(설계를 하다보면 필요한 내용들이 생길 수 있음.)
기본/키: 본래 업무에 존재하는 정보. 독립 생성 가능. 주식별자 보유 : 직원, 고객, 상품중심: 기본 개체로부터 발생. 업무에 있어 중심 역할 : 주문, 매출, 계약행위: 2개 이상 개체로부터 발생 : 주문이력
2. Attribute(속성) 이해하기
속성: 업무상 관리하기 위해 의미적으로 더는 분리되지 않는 최소의 데이터 단위, 개체가 가지는 공통적인 특징이기도 한다. ex) ID, salary, department, Birth, name…
식별자: 개체 내 unique한 인스턴스를 식별할 수 있는 속성의 집합
Domain: 각 속성이 입력 받을 수 있는 값의 정의 및 범위 ex) 나이는 0~999까지의 숫자만 입력 받을 수 있다, 이름은 최대 X자리의 문자열만 받는다.
이것도 Class Attribute처럼 개체의 속성으로 이해하면 편하다. pandas를 해봤다면 table의 column으로 보면 된다.
특성에 따른 Attribute의 분류
특성에 따른 분류
기본: 업무로부터 추출한 속성으로 제일 많이 발생한다.설계: 설계시 규칙화 등이 필요해 만든 속성. 코드성이나 일련번호 등. 부서나 소속을 편하게 D001, D002 이런 식으로 명명함.파생: 다른 속성들로부터 계산/변형되어 만들어진 속성(실무에 안 쓰는 걸 권장) aggregation 등 집계함수로 계산된 결과등이 여기에 속한다.
구성에 따른 Attribute 분류
구성에 따른 분류. 이에 대한 내용은 데이터모델링에서 자세히 다룸.
- PK(Primary Key)
- FK(Foreign Key)
- 일반속성
- 복합속성 : 여러 개의 정보를 담는 경우(주소같은 거)
3. Relationship(관계) 이해하기
관계: 엔터티 내의 인스턴스들 간에 서로 논리적인 연관성이 있는 상태
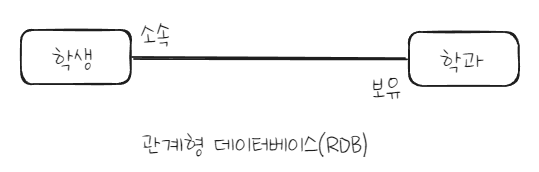
- ERD(Entity-Relationship Diagram)은존재/행위 등 관계를 위 그림처럼 표시한다.
- UML class diagram의 경우
- 연관관계(존재)는 실선으로 표기
- 의존관계(행위)는 점선으로 표기
관계를 표시하는 방법
- ERD 표기하는 방식은 2가지가 있다.
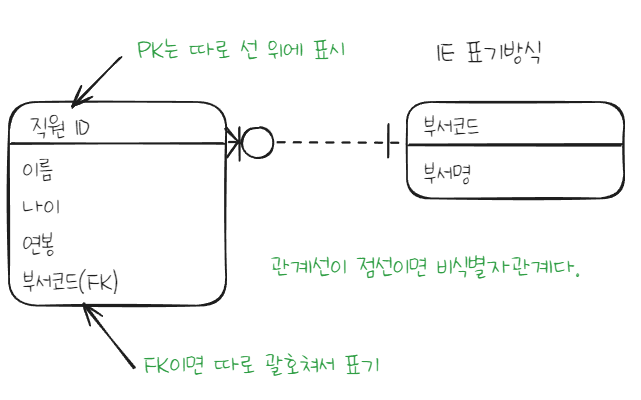
- ==IE 타입==은 웬만하면 시험에 나온다.
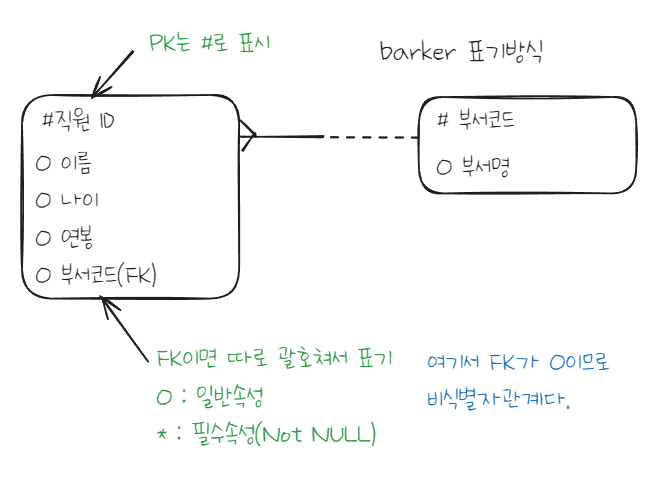
- Barker 타입은 가끔 실무에 나오는 정도
표시방법은 총 3가지 키워드만 기억해두면 된다.
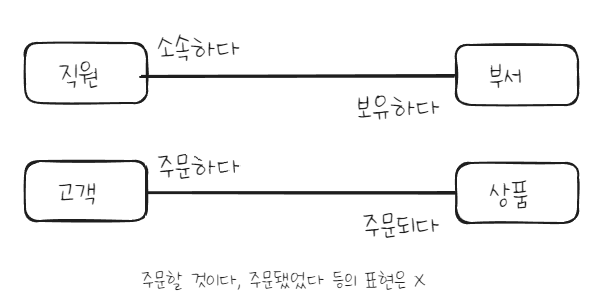
1. 관계명(Membership)
관계명을 표시한다. 이 때 애매한 동사나 과거형은 피한다. (IE, barker 방식 동일)
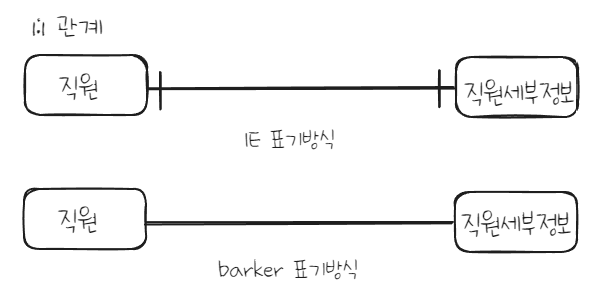
2. 관계차수(Cardinality/Degree)
관계차수는 엔터티 내 각 인스턴스들이 얼마나 참여하는지 의미한다.
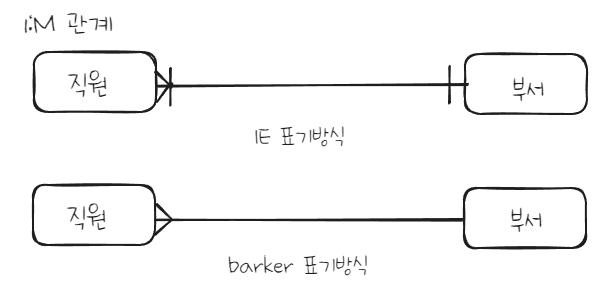
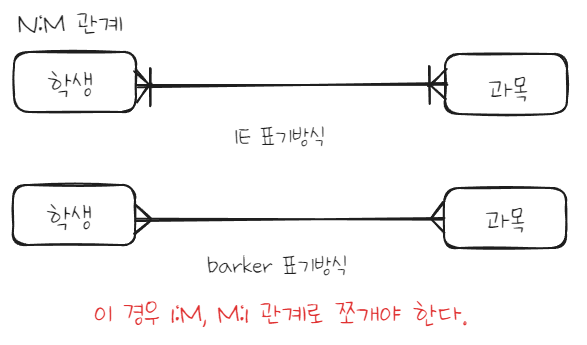
N:M 관계를 쪼개는 방법은 식별자를 넘겨주면서 새 테이블 만드는 방식을 추천한다. 관계에 대해서는 아래 블로그 링크 참고해보자.
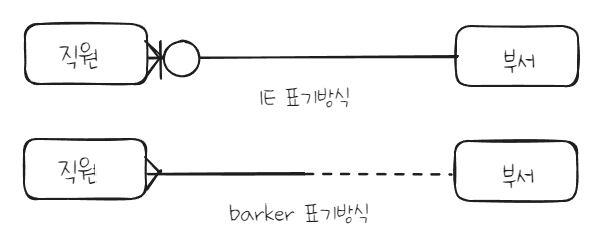
3. 관계선택사양(Optionality)
관계선택사양은 엔터티 내 각 인스턴스들이 필수/선택 참여하는지를 의미한다.
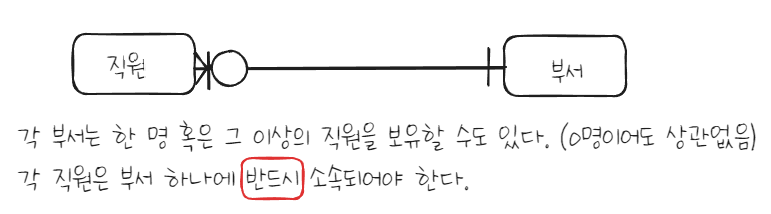
필수/선택에 대한 표기는 IE/barker 방식이 가장 차이난다.
코드성, 통계성이란?
보통 관계가 없는 엔터티는 쓸모 없는 것으로 취급된다.
코드성: 어떤 값들을 코드 형식으로 저장해서 쓰기 편하게 만드는 것- ex) 남/여 로 표현할 수도 있는데 그냥 1/2로 표기한다. (간결하게 하려고)
통계성: 해당 엔터티만으로도 유의미한 정보를 담고 있는 경우 통계성 있다고 하며 관계가 없어도 의미가 있는 것으로 취급한다.- ex) 월별 매출 등
데이터 모델링
현실세계의 복잡한 대상을 단순하게 표현하기 위해 추상화, 단순화, 명확하하여 일정표 기법으로 표시
- 계획/분석/설계 시 업무분석 및 설계, 설명에 사용
- 구축/운영시에는 변경, 관리 목적으로 사용한다.
데이터 모델링은 3단계로 나뉜다.
- 개념적 데이터 모델링
- 논리적 데이터 모델링
- 물리적 데이터 모델링
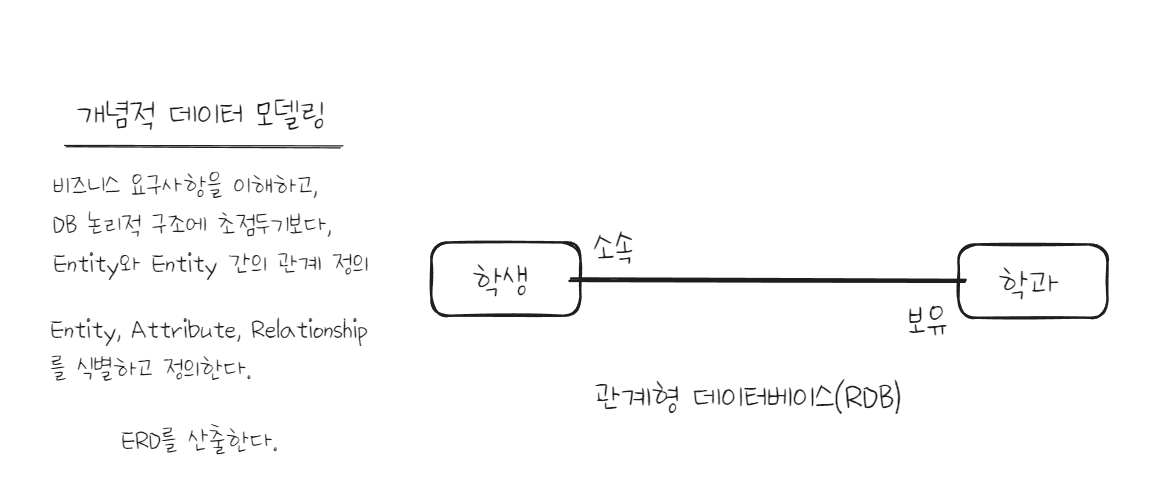
추상적, 업무중심적, DMBS 독립적
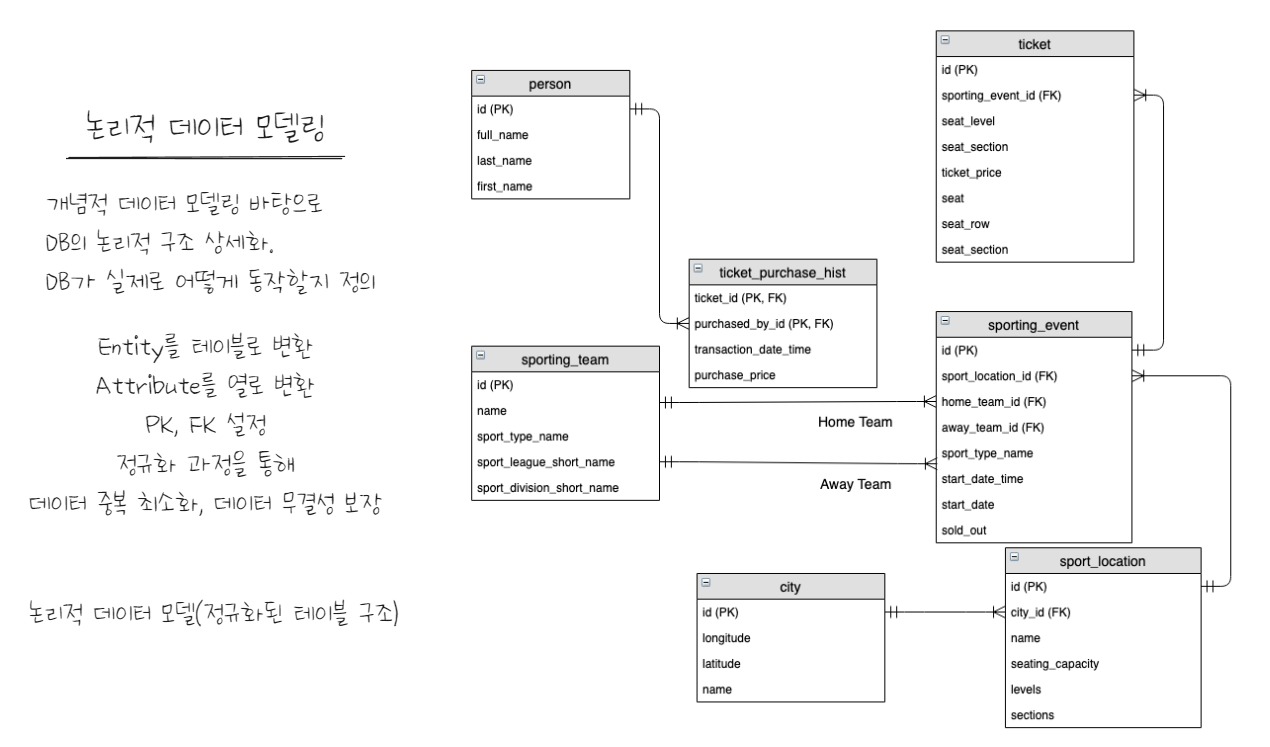
Key, 업무, 속성 관계 등 정의하며 재사용성이 높다. 그리고 특정 DBMS에 종속적이다. 식별자 선택 $\sim$ PK, FK
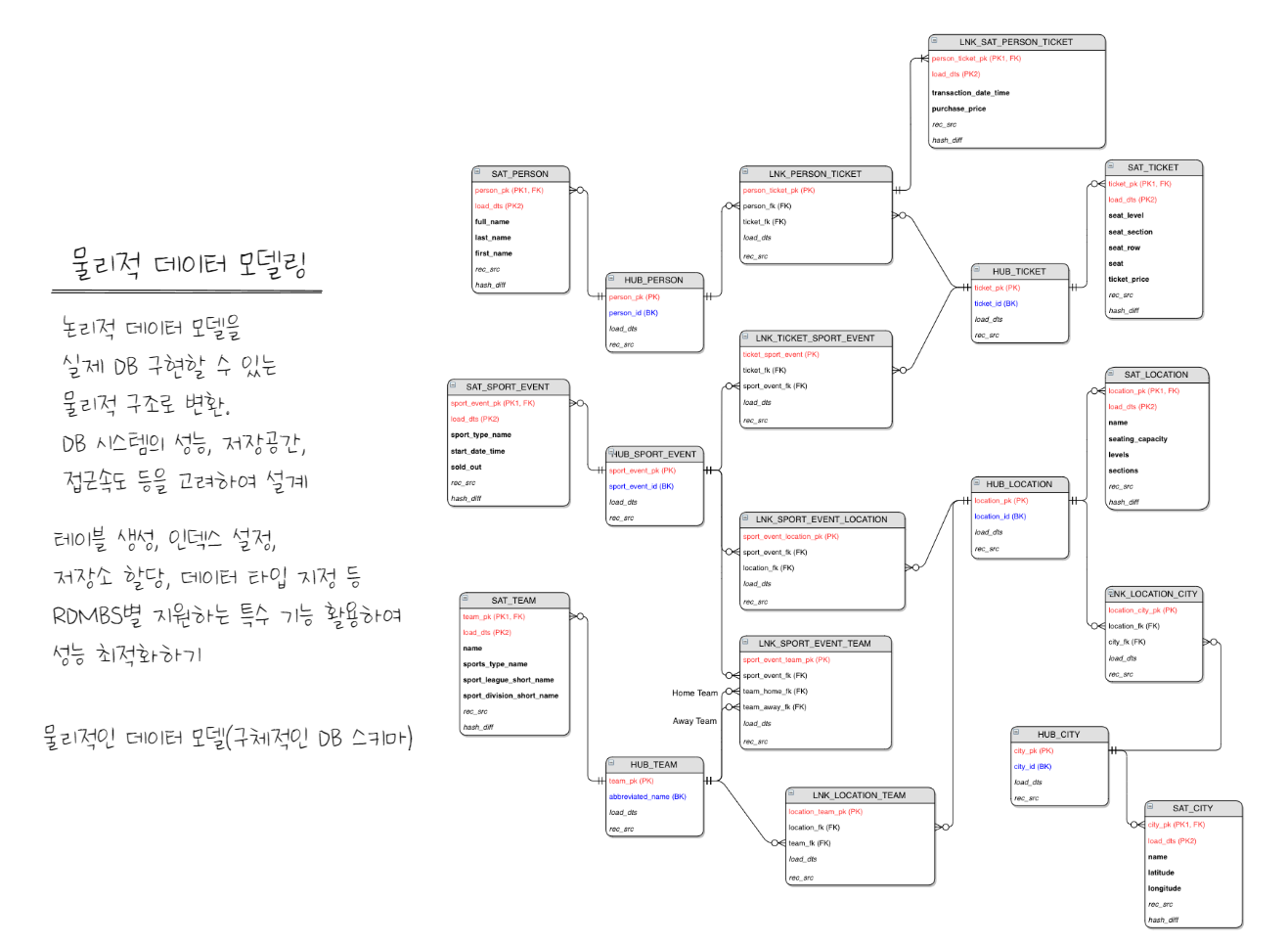
ERD(Entity-Relationship Diagram)
엔터티와 엔터티 간의 관계를 발견하고 이를 그림으로 표현하는 행위로 ==개념적== 데이터 모델링의 결과물이다.
개념적, 논리적, 물리적 데이터 베이스 모델링은 여기 강의에서 잘 설명해주니 어떻게 할지 감이 안 잡히면 여기서 보자.
데이터 모델링이 중요한 이유?
- 파급효과 : 설계부터 확실하게 하여 나중에 갈아 엎는 일이 없게 해야함.
- 간결한 표현 : 서로 의사소통을 위해 모델링된 설계도(ERD 등)으로 쉽게 이해
- 데이터 품질 : 데이터 모델링을 함으로써 중복된/유연하지 못한/일관적이지 못한 데이터를 거를 수 있다. (정규화를 해서 데이터 품질을 높임)
- 복수 PK가 유연하지 못하면 데이터 정의를 바꿔야 하는 순간이 올 수 있다.
논리적 모델링 표기법 2가지
데이터 베이스 3단계 구조
시험에 객관식 보기로 나온다고 하니 참고
- 외부(External) 스키마 : 여러 사용자 각각의 관점 (독립적이다.)
- 개념(Conceptual) 스키마 : 통합적, 조직 전체의 DB 관점
- 내부(Internal) 스키마 : 데이터 물리적 저장 구조를 표현
외부 스키마는 개발자말고 일반 사용자 관점이라고 보면 된다. 어떤 속성이 추가되었고 편집되었는지 전체 구조를 알 수 없다.
식별자
식별자(identifiers) : 엔터티 내 유일하게 인스턴스를 식별할 수 있는 속성의 집합.
Primary Key로 생각해도 좋다.
식별자 분류
- 대표성 여부 : 주식별자 vs 보조식별자
- 스스로 생성여부(자생여부) : 내부식별자 vs 외부식별자(다른 엔터티에서 빌려온 식별자)
- 단일속성여부 : 단일식별자 vs 복합식별자(2개 이상의 식별자)
- 대체여부 : 본질식별자 vs 인조식별자(SAMPLE1, SAMPLE2… 와 같이 편의상 식별자 이름을 지어냄)
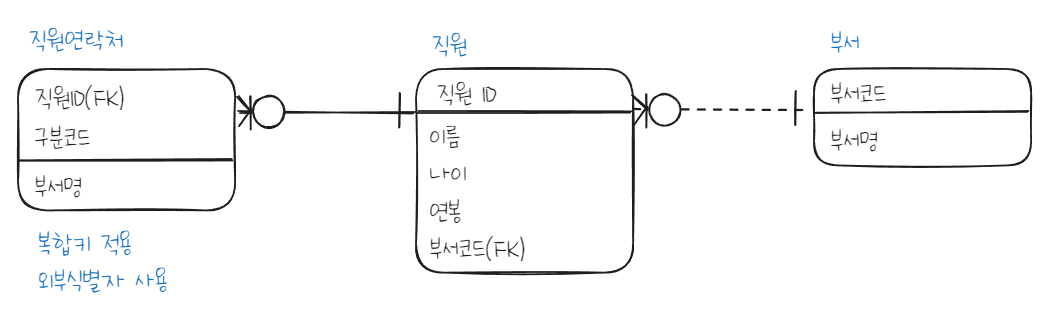
- 주식별자 도출기준은? ex) 왜 주민등록번호 대신 직원ID 사용할까?
Reference
- ⭐가장 많이 참고한 강의1 SQLD youtube 링크 모음
- 데이터 모델링 wikidocs
- AWS 논리적DB vs 물리적DB : DB 그림 참고